



Photo by Souvik Banerjee on Unsplash
Crack the Code of the Twitter Recommendation Algorithm with This Decoded Explanation! 🧐


Twitter open-sourced the code for their Recommendation Algorithm. This algorithm is responsible to find, rank, and show you relevant tweets on your For You timeline.
For creators that is amazing news as it makes the platform more transparent.
For developers, it’s an opportunity to learn from the “best”. The code is available on GitHub and anyone can have a look at it. If only we can understand it…
I did my graduation project on this topic and built a recommendation system for a social media application leveraging AWS Personalize. I also had the opportunity to work at a small part of Amazon’s recommendation algorithm during my internship. From that experience, I understood that Recommendation systems are no easy task.
Companies invest a lot of money and resources in developing good recommendation systems because it directly impacts the bottom line of the business. The better content is recommended to users, the more “hooked” they become and the more time they spend in the app. More time in the app, more ads are shown. More ads - more revenue.
How does it work?
From a high-level perspective, Twitter’s Recommendation Algorithm is a pipeline made of 3 stages:
Source “relevant tweets”
Rank them
Filter out (remove NSFW and blocked/muted people)
Let’s dive deeper into each stage of the pipeline.
1. Sourcing
Every time we request a new timeline feed, the pipeline starts with sourcing relevant tweets to show you. It gathers roughly 1500 out of hundreds of millions of tweets.
The question is, how relevant tweets are found?
50% from people you follow (In-Network)
50% from people you don’t follow (Out-of-Network)
The In-Network source is easy to grasp. If you follow a person - you are basically saying I am interested in this user and I would like to see his tweets. However, not all users you follow will have an equal chance to appear in your timeline. During this phase, all recent tweets from people you follow will be ranked using a model that can predict how likely you are to be interested in that tweet.
The challenging part is the other half of the tweets you see. Tweets from Out-of-Network sources - from people you don’t follow.
Some of the tweets here (15%) are sourced from the social graph. In simple words, the algorithm is looking for tweets that people you follow to engage with.
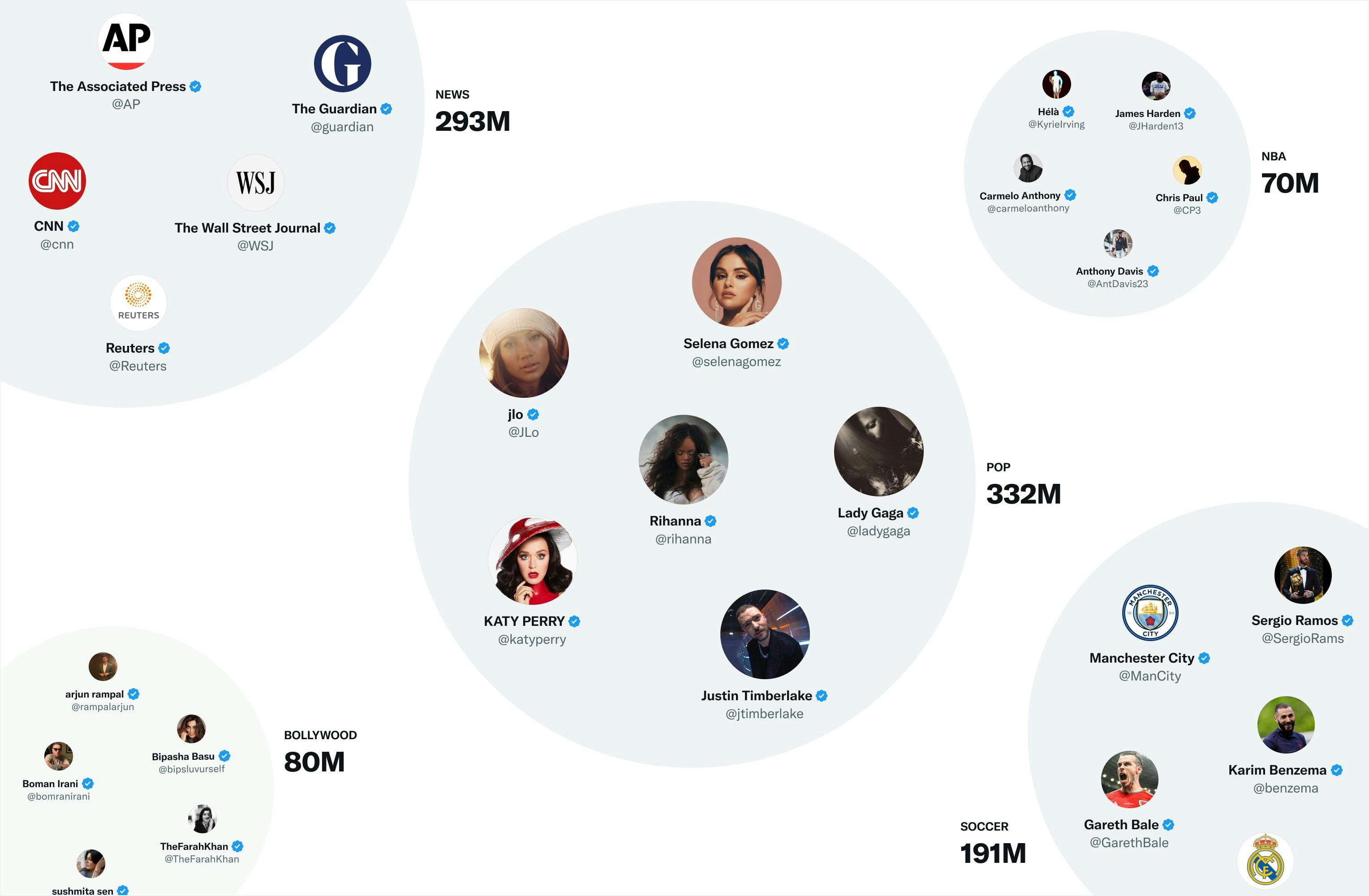
The rest 35% of tweets are sourced from Embedding spaces. Here, the algorithm is categorizing all the users and tweets into big buckets called spaces (think about it as communities). So, if you show interest in the Pop community, the algorithm will push popular tweets from that community.
Here we can see a representation of some of the biggest communities:
2. Ranking
So far, the algorithm has gathered ~1500 “relevant” tweets. Now, it’s time to rank them.
This is done by a Machine Learning model that is trained to predict and score how likely a tweet will receive positive engagement from you (like, retweet, reply, etc.)
Let’s think about this stage as a Talent Show, where 1500 participants fight for your attention.
There are multiple judges, and everyone is responsible for judging one single aspect of the candidate:
How often does the user interact with the author?
How much interest does the user have in this type of content?
Is the author a Twitter Blue subscriber?
Now, every participant presents in front of the judges and receives a grade from each of them.
The thing is, that every judge has different voting power. For example, the judge responsible for the number of likes has a voting power of 30. The one is responsible for retweets - 20. And what’s funny, is that there is also a judge responsible for Twitter Blue status that has a voting power of 2 (that one you can easily bribe).
In the end, the final score of a participant is the sum of the points received from every judge which is equal to the grade multiplied by the voting power of that judge.
3. Filtering
Now that we have a list of 1500 ranked tweets, the last step is to get rid of the majority of them and leave only a handful that will be shown to you.
This is done by applying various filters for NSFW, offensive, or content flagged as misinformation.
Also, here is where tweets from people you muted/blocked are removed.
The final goal of this phase is to provide a balanced and diverse feed to the user, based on his preferences.
Here are your tweets, Sir
The last step is to sprinkle some ads here and there and deliver the final feed to your device.
But HoW SCalabLe iS iT?
They say that the pipeline runs approximately 5 billion times per day and completes in under 1.5 seconds on average.